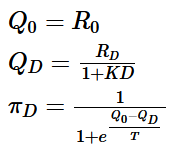The task involved three phases. In phase 1, subjects made a series of temporal discounting decisions that we used to estimate their initial value K1 in a standard hyperbolic discounting model. The index 1 stands for phase 1 of the experiment, before learning about another individual. According to this model, the value of a reward RD given after a delay D is VD=RD/(1+KD) where K is the hyperbolic discounting parameter.
In phase 2, they learned to make choices expressed by another, simulated, participant whose K = Ko differed from theirs. Finally, in phase 3, they made more choices for themselves and the other, allowing us to assess whether their K3 ≠ K1 had changed (3 here indexes phase 3, after exposure to the partner). The Ko of the simulated participant was set to be systematically larger or smaller than K1 by a modest amount in order to provide the temptation to change.
In detail, we approximated the behaviour of participants and simulated the ‘other’ using hyperbolic value discounting followed by a softmax rule: